Les opérations collectives
Un opération collective est une opération parallèle qui implique la communication de données entre plusieurs processus. Dans le TP1, vous avez implémenté l'opération collective de diffusion ou broadcast avec plusieurs algorithmes. Vous avez également vu la primitive MPI proposant cette fonction MPI_Bcast. Les opérations collectives les plus répandues sont :
MPI_Bcast;MPI_ReduceetMPI_Allreduce;MPI_ScatteretMPI_Scatterv;MPI_GatheretMPI_Gatherv.
Vous connaissez déjà le broadcast, vous trouverez des explications sur scatter, gather et allgather ici et sur reduce et allreduce ici.
MPI_Gatherv
La fonction MPI_Gatherv sert comme MPI_Gather à réunir les données de différents processus dans un même tableau sur le processus racine. La différence avec MPI_Gather est que les données provenant des différents processus peuvent être de taille différentes. Cela implique que le processus racine connaisse la taille de chacun des tableaux envoyés par les autres processus. Il faut également fournir à la fonction où stocker chaque tableau dans le tableau destination. L'opération MPI_Gatherv est représentée sur le schéma suivant:
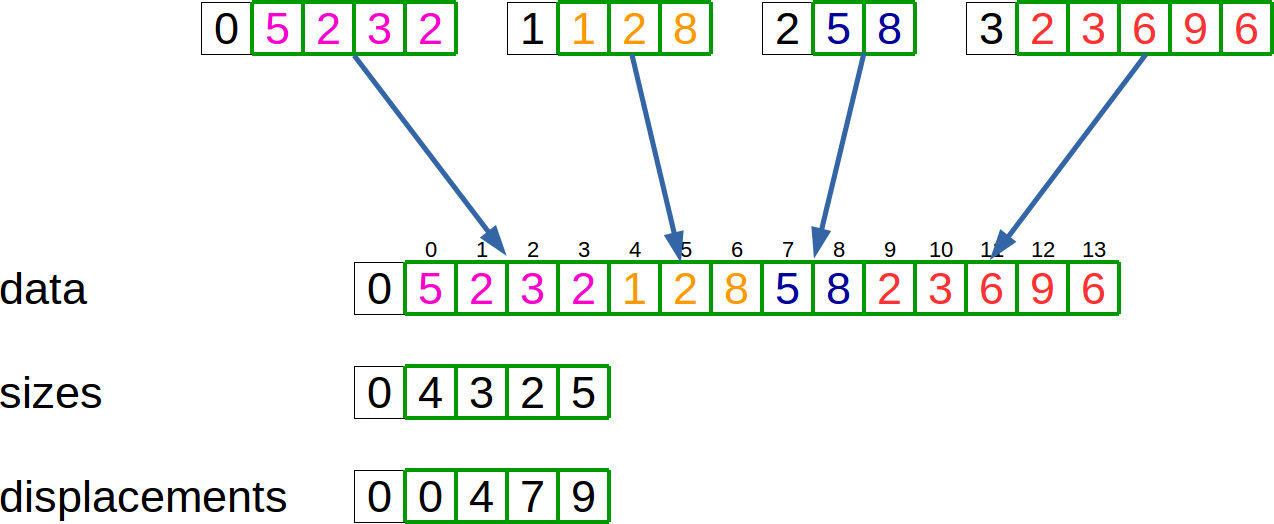
Dans ce cas, chaque processus envoie son tableau local au processus 0 qui le stocke dans data. Le tableau sizessur le processus 0 contient la taille des données reçues et le tableau displacements spécifie où chaque tableau local doit être stocké dans le tableau global.
En général, le processus racine ne connaît pas la taille de chaque tableau à recevoir. Dans un cas comme ça, il est donc nécessaire de réunir (avec un MPI_Gather) les différentes tailles avant d'appeler la fonction MPI_Gatherv. Le code suivant donne une exemple d'utilisation de la fonction MPI_Gatherv :
std::vector<int> sizes;
std::vector<int> dataGlobal;
std::vector<int> displacements;
int sizeGlobal = 0;
int sizeLocal = dataLocal.size();
if(myRank == 0) sizes.resize(nProc);
// reunion des tailles locales
MPI_Gather(&sizeLocal, 1, MPI_INT, sizes.data(), 1, MPI_INT, 0, MPI_COMM_WORLD);
// calcul du vecteur de deplacement et allocation du tableau global
if(myRank == 0){
displacements.push_back(0);
for(int i=0; i<sizes.size(); i++){
displacements.push_back(displacements[i]+sizes[i]);
sizeGlobal += sizes[i];
}
dataGlobal.resize(sizeGlobal);
}
// reunion des donnees
MPI_Gatherv(dataLocal.data(), sizeLocal, MPI_DOUBLE, dataGlobal.data(), sizes.data(), displacements.data() , MPI_INT, 0, MPI_COMM_WORLD);MPI_Scatterv
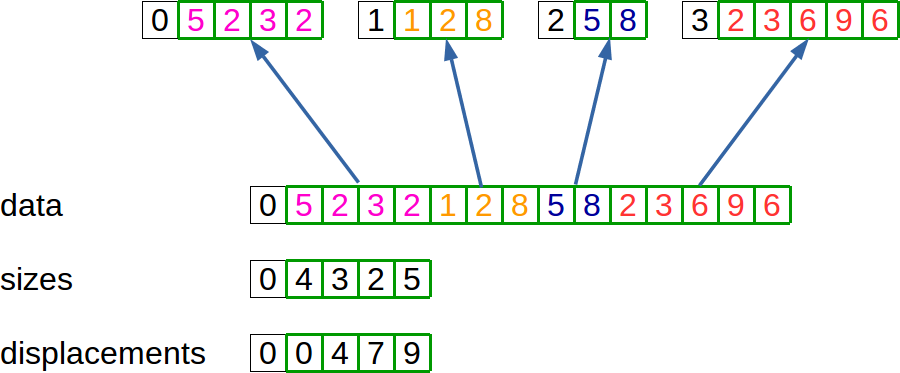
Le MPI_Scatterv de la même façon permet de répartir des données à chaque processus depuis un processus source en attribuant une taille de donnée différente à chaque processus. Le schéma suivant illustre cette opération:
MPI_Sendrecv
Le MPI_Sendrecv permet d'envoyer et de recevoir une donnée lors de la même opération. Cette fonctione permet d'éviter de simplifier et d'éviter les interblocages lors d'échanges entre deux processus.
Documentation et exemple d'utilisation :
#include <mpi.h>
#include <iostream>
#include <vector>
#include <cassert>
int main(int argc, char **argv) {
int myRank, nProc;
MPI_Status status;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myRank);
MPI_Comm_size(MPI_COMM_WORLD, &nProc);
assert(nProc==2);
std::vector<int> send(1000000, myRank);
std::vector<int> recv(1000000, -1);
int dest=0;
if(myRank==0) dest=1;
MPI_Sendrecv(send.data(), send.size(), MPI_INT, dest, 999, recv.data(), recv.size(), MPI_INT,
MPI_ANY_SOURCE, 999, MPI_COMM_WORLD, &status);
std::cout << "I'm process " << myRank << " and last element of my received vector is " << recv.back() << std::endl;
MPI_Finalize();
}éviter le deadlock:
#include <mpi.h>
#include <iostream>
#include <vector>
#include <cassert>
const int nbEnvois = 8;
int main(int argc, char **argv) {
int myRank, nProc;
MPI_Status status;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myRank);
MPI_Comm_size(MPI_COMM_WORLD, &nProc);
assert(nProc==2);
int size = 1;
for (int iSize=1; iSize<nbEnvois; ++iSize) {
std::vector<int> buffer(size);
if (myRank == 0) {
std::cout << "Envoi d\'un message de " << size << " entiers" << std::endl;
MPI_Send(buffer.data(), size, MPI_INT, 1, 0, MPI_COMM_WORLD);
MPI_Recv(buffer.data(), size, MPI_INT, 1, 0,MPI_COMM_WORLD, &status);
}
else {
MPI_Send(buffer.data(), size, MPI_INT, 0, 0, MPI_COMM_WORLD);
MPI_Recv(buffer.data(), size, MPI_INT, 0, 0, MPI_COMM_WORLD, &status);
}
size *= 10;
}
if (myRank == 0) {
std::cout << "Fin des envois" << std::endl;
}
MPI_Finalize();
}